When data is sent through a FreeRTOS queue, the scheduler performs a block-by-block copy of the data. This approach ensures thread-safe operations for both adding and removing data, effectively preventing race conditions. However, one potential drawback is the CPU overhead associated with the copying process. In systems with constrained SRAM or limited CPU resources, transmitting large volumes of data via queues may be inefficient or impractical.
A common scenario where a FreeRTOS queue may not be the most efficient choice for data synchronization is the interaction between a UART interrupt service routine (ISR) and a lower-priority task responsible for processing received data. Sending one byte at a time from the ISR to the task using a queue can lead to inefficient CPU usage and unnecessary SRAM overhead due to the per-byte copying and queue management. In such cases, alternative buffering strategies that use global variable arrays can offer better performance and SRAM utilization. Two such methods will be discussed below.
Double Buffering
Double buffering is a commonly used technique for transferring data between tasks. This method involves allocating two memory buffers and using two pointers to manage access to the buffers. Typically, one task (or an interrupt service routine) acts as the producer, writing data into one buffer, while a second task serves as the consumer, reading from the other buffer. By alternating the roles of the buffers, double buffering enables efficient data exchange without the overhead of copying data through a queue, while also minimizing contention between tasks.
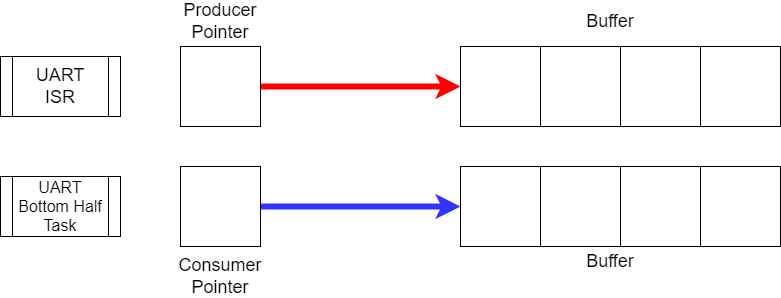
The key to double buffering is ensuring that the producer and consumer never access the same buffer simultaneously. While the producer writes data to one buffer, the consumer must only read from the other buffer. This separation prevents race conditions by guaranteeing that each buffer is accessed by only one task at a time.
When the producer determines that the current buffer is ready for processing, it swaps the roles of the two buffers. This buffer swap must be performed atomically to avoid inconsistencies. One approach is to enter a critical section, during which the producer safely updates the buffer pointers. Another common method is to assign the producer a higher priority than the consumer. In this case, the producer can safely perform the swap without interruption, since the lower-priority consumer cannot preempt it during the operation.
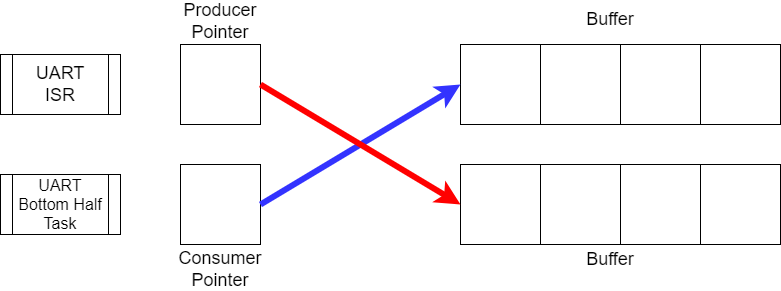
When implementing a double buffering strategy, several important factors must be considered to ensure reliable and efficient data transfer between tasks:
- Producer Awareness:
The producer must be able to determine when the data in its buffer is ready to be consumed. The simplest approach is to swap buffers when the producer buffer is full. In cases where data follows a structured format—such as multi-byte packets—the buffer swap can occur once a complete packet has been received. - Consumer Processing Time:
The consumer must be able to process the data in its buffer before the next buffer swap occurs. Double buffering is commonly used for serial data reception, where the producer (e.g., a UART ISR) receives data at a relatively slow rate, while the consumer task runs at core CPU speed. Since CPU speeds are typically 20 to 1000 times faster than serial data rates, the consumer usually has ample time to process the data before the next swap. - Avoid Polling:
The consumer task should not continuously poll the buffer for new data, as polling is inefficient and wastes CPU cycles. Instead, the producer should use a FreeRTOS synchronization mechanism—such as a task notification, semaphore, or event group—to signal the consumer when data is ready. This ensures the consumer only runs when necessary, improving system responsiveness and efficiency.
Circular Buffers
Double buffering is well-suited for structured data transfers where blocks of data are uniform in size and follow a predictable pattern. However, when the size of the data being transmitted varies, a circular buffer may be a more appropriate solution. A circular buffer is a fixed-size array that wraps around when the end is reached, allowing data storage and retrieval without the need for shifting elements. Circular buffers are particularly effective in scenarios where data arrives at irregular intervals or in variable-length chunks, such as serial communication or streaming input. They allow the producer to write data into the buffer while the consumer reads from it, using separate read and write indices to track positions. This structure minimizes memory usage compared to other data storage methods such as a linked list.
The key to using a circular buffer lies in understanding how data is added and removed. Data is written into the buffer using a counter known as the produce count, which tracks how many items have been added to the buffer. After each write operation, the produce count is incremented. Similarly, data is read from the buffer using a consume count, which tracks how many items have been removed. Like the produce count, the consume count is incremented after each read. A crucial detail is that neither counter is ever reset to zero; instead, they continue to increment indefinitely. The actual buffer index is calculated using a modulo operation with the buffer size, allowing the counters to wrap around the array.
To determine where to insert the next piece of data in a circular buffer, the modulo operation is used with the produce count and the buffer size. This ensures that the index wraps around when the end of the buffer is reached. For example, consider a circular buffer with a size of 4. If four characters have already been added, the produce count is equal to 4. To find the index for the fifth character, we compute (4 % 4 = 0). This result indicates that the next character will be inserted at index 0, effectively wrapping around to the beginning of the buffer.
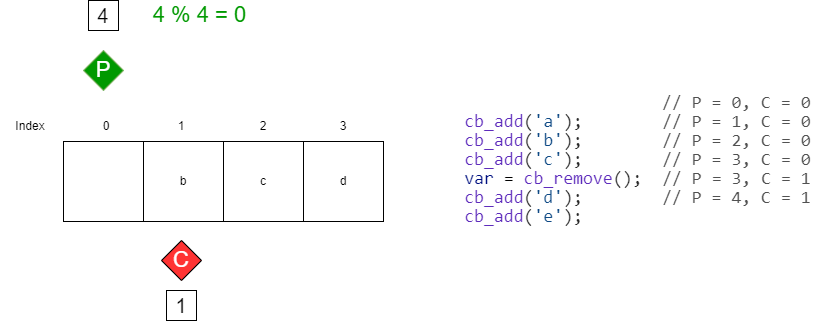
The consume count works in the same way. By taking the modulo of the consume count, we can determine where the next entry in the array will be removed.
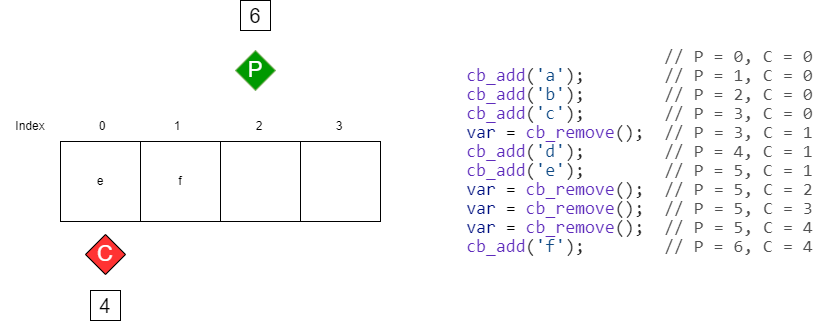
For a circular buffer to operate correctly, we need to know how to correctly calculate produce and consume indices and also how to determine if the buffer is full or empty.
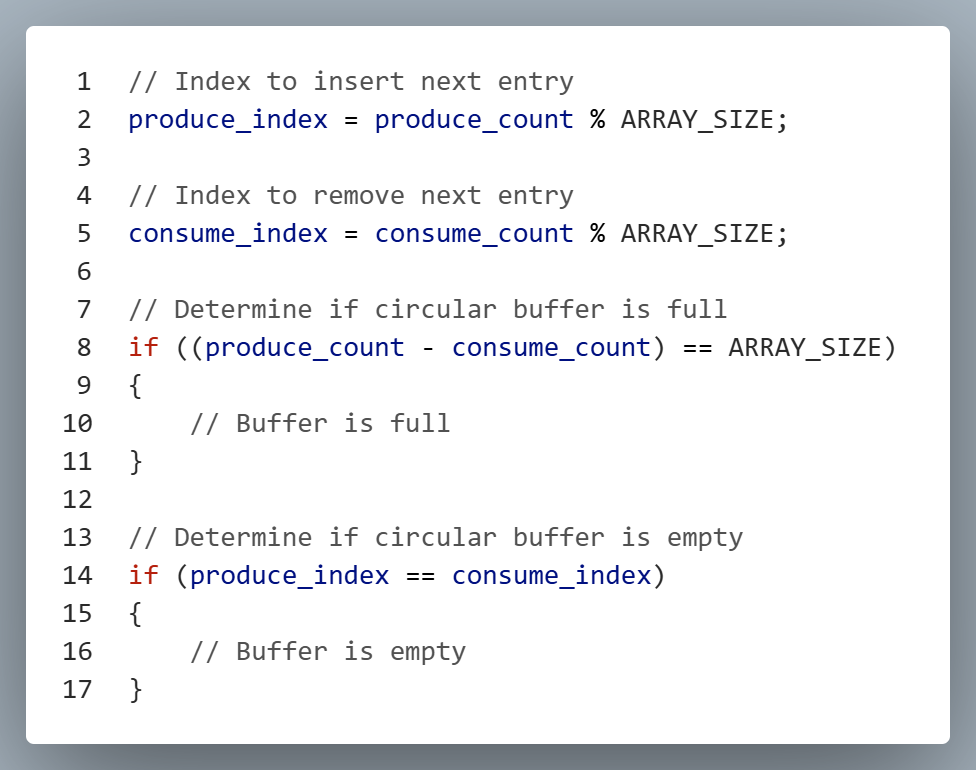
When using a circular buffer, developers must ensure that data is not added when the buffer is full and not removed when the buffer is empty. Failing to check these conditions can lead to data corruption or unexpected behavior. Another critical aspect is ensuring that updates to the produce and consume counts are performed atomically. Interrupt service routines (ISRs), which typically run at a higher priority than FreeRTOS tasks, can safely modify these counters without being interrupted. However, when a FreeRTOS task modifies either count, it must enter a critical section to prevent race conditions. This guarantees that the operation completes without interference from other tasks or ISRs, preserving data integrity.
Double Buffering vs Circular Buffer
| Feature | Circular Buffer | Double Buffering |
|---|---|---|
| Memory Efficiency | Fixed-size buffer with continuous reuse; | Uses two buffers; efficient for structured data |
| Supports Variable Data Sizes | Yes — ideal for irregular or variable-length data | Limited — best for fixed-size or structured data blocks |
| Producer-Consumer Separation | Separate read/write indices allow concurrent access | Producer and consumer use separate buffers |
| Synchronization | Requires careful management of counters and atomic updates | Buffer swap must be atomic |
| Ideal Use Cases | Streaming data, UART, audio, sensor input | Structured data packets, frame-based communication |
| Scalability | Easily scalable to larger buffers | Scales well for predictable data patterns |
| Polling Avoidance | Can use synchronization primitives to avoid polling | Same — producer can signal consumer when data is ready |
| Implementation Complexity | Moderate — requires careful index and overflow handling | Simple — two buffers and pointer swapping |