Overview
A queue is a data structure that maintains an ordered list of elements, where the number of entries can vary depending on the needs of the application. It is commonly used to manage data in the order it arrives.
When data is added to a queue, it is added to the end(tail) of the queue. Data can be added to the queue until the queue becomes full. Data is removed from the front (head) of the queue. This behavior enforces a FIFO (First In, First Out) data management scheme that helps tasks to organize data based on the order that it arrives.
The diagram below shows add and removing data from a queue with a length of 4 elements.

FreeRTOS Queue Implementation
FreeRTOS adds data to a queue using what is called Queue-by-Copy. What this means is that data sent to a FreeRTOS queue is byte-for-byte copied into the queue. To understand why Queue-by-Copy was used in FreeRTOS, you can examine the following information from the FreeRTOS documentation:
FreeRTOS uses the queue by copy method because it is both more powerful and simpler to use than queueing by reference because:
- Queuing by copy does not prevent the queue from also being used to queue by reference. For example, when the size of the data being queued makes it impractical to copy the data into the queue, then a pointer to the data can be copied into the queue instead.
- A stack variable can be sent directly to a queue, even though the variable will not exist after the function in which it is declared has exited.
- Data can be sent to a queue without first allocating a buffer to hold the data—you then copy the data into the allocated buffer and queue a reference to the buffer.
- The sending task can immediately re-use the variable or buffer that was sent to the queue. The sending task and the receiving task are completely de-coupled; an application designer does not need to concern themself with which task ‘owns’ the data, or which task is responsible for releasing the data.
- The RTOS takes complete responsibility for allocating the memory used to store data.
[1] Mastering the FreeRTOS Real-Time Kernel v1.1.0, Pg 99
Queues Vs Global Variables
Queues are commonly used for inter-task communication in an RTOS. Queues have several important advantages over global variables which make them the preferred way to share information between tasks in an RTOS.
Atomic Operations
Queues are designed to add and remove data in a thread safe manner. The API functions are written so that copying data to or from a queue occurs as an atomic operation. This helps to prevent many of the race conditions and need for synchronization commonly associated with using global variables.
Decoupling Tasks
Utilizing a queue promotes loose coupling between tasks. The task that produces data does not need to know how the data will be processed or who will consume it. This separation leads to simpler, more modular code, allowing each task to focus solely on its specific role.
Blocking on A Queue
Queues allow a task to enter the Blocked state when there is no data to consume, enabling the CPU to focus on other Ready tasks. This approach is more efficient than continuously polling a global variable, which wastes CPU cycles. By using queues, the system can respond to data availability through event-driven scheduling, improving overall responsiveness and resource utilization.
FreeRTOS Creating a Queue
In FreeRTOS, a queue is accessed through a handle of type QueueHandle_t. This handle is typically declared as a global variable so that multiple tasks can access the same queue. By sharing the handle globally, tasks can safely send and receive data through the queue without needing direct references to each other.

A FreeRTOS queue must be initialized before any task attempts to send or receive data. It is strongly recommended to create all queues before starting the scheduler. Doing so ensures that tasks do not access uninitialized or invalid memory, which could lead to system crashes.
In the example below, the queue handle is initialized with a length of 10, meaning it can hold up to 10 items. The data type stored in the queue is user-defined, allowing flexibility based on application needs. In this case, the queue is designed to hold values representing the direction of a joystick.

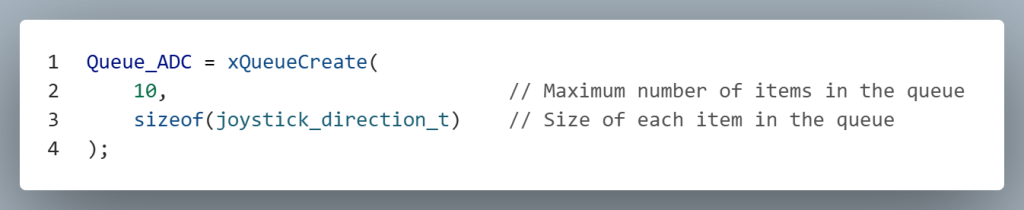
FreeRTOS Task Sending Data to a Queue
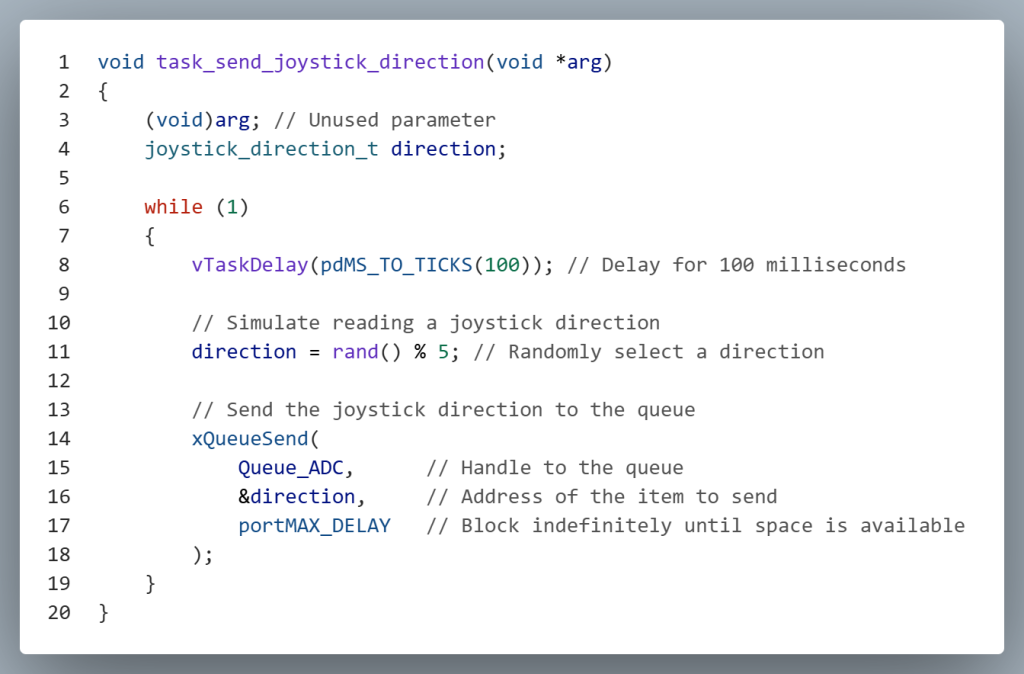
Data is added to a queue using the xQueueSend() function.
Parameters:
- The first parameter is the handle of the queue where data will be sent
- The second parameter is the memory address of the data being added to the queue.
- The third parameter specifies how long to wait for the queue to have space available to add the data. Passing portMAX_DELAY tells the task to wait indefinitely.
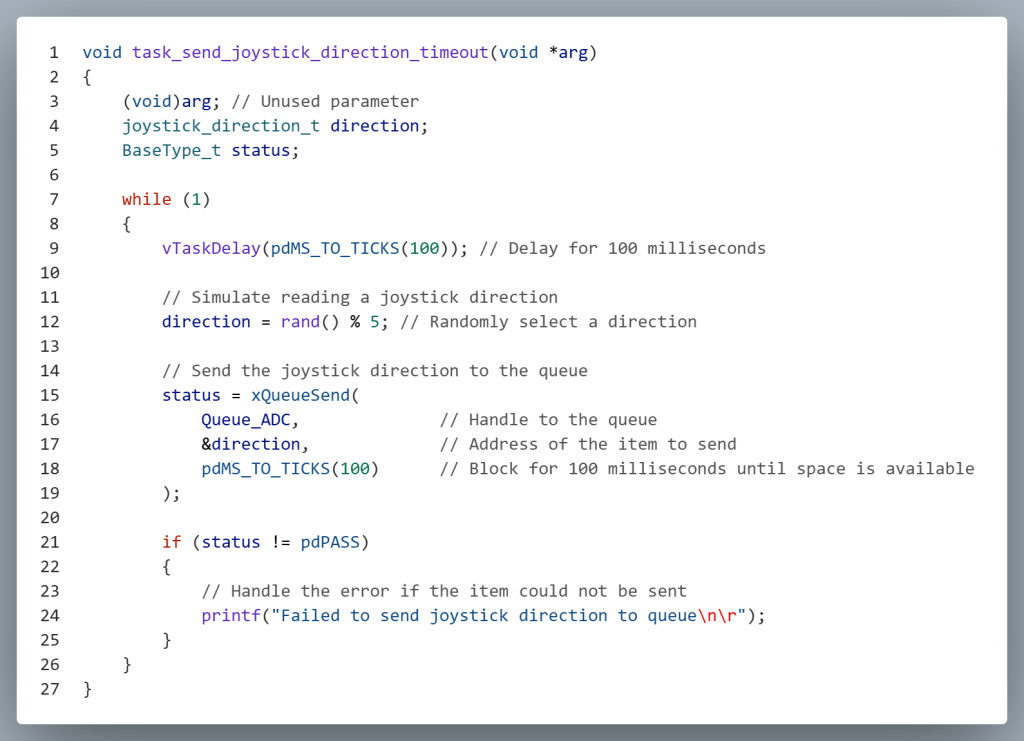
If a task cannot wait indefinitely for space in the queue, the third parameter of xQueueSend() can be set to a specific timeout value. If space becomes available within that timeout period, the data is successfully added to the queue and the function returns pdPASS. If the queue remains full for the entire duration, the function returns pdFAIL, allowing the task to handle the failure appropriately—such as retrying, logging an error, or taking alternate action.
FreeRTOS Task Receiving Data from a Queue
Data can be received from a FreeRTOS queue using the xQueueReceive() function.
Parameters:
- The first parameter is the handle of the queue from which data will be received.
- The second parameter is the memory location where the received dtaa will be stored.
- The third parameter specifies how long the task should wait for data to become available. Passing portMAX_DELAY causes the task to block indefinitely until data is received
It is important to allocate memory for the variable that will hold the received data. In this example, a local variable is used to store the most recent item retrieved from the queue.

Sending/Receiving Large or Variable Sized Blocks of Data
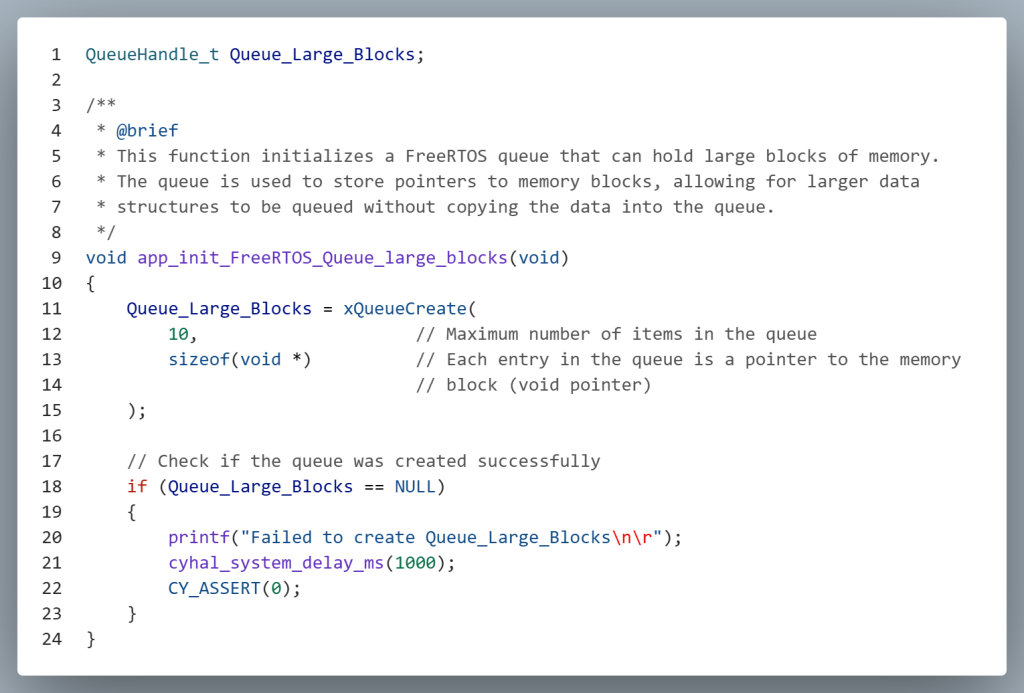
In situations where the data being transmitted between tasks is large, using the Queue-by-Copy method may introduce unacceptable latency due to the overhead of copying each byte. To address this, designers can use a Queue-by-Reference approach, where the queue transmits a pointer to the data rather than the data itself. This method significantly reduces transmission time by avoiding the need to copy large blocks of data, making it ideal for performance-critical applications. The code fragments that follow will illustrate how to make use of Queue-by-Reference.
Initializing a queue for Queue-by-Reference is similar to the standard approach. The key difference lies in the third parameter of the xQueueCreate() function, which specifies the size of each item in the queue. For Queue-by-Reference, this parameter should be set to the size of a pointer (typically sizeof(void *)). This allows the queue to store addresses pointing to data of any type, enabling efficient transmission of large data blocks without copying the actual contents.
The task responsible for sending data must also be modified when using the Queue-by-Reference approach. The most important change is that large data blocks should be allocated from the heap rather than the stack. Since each task has a limited stack size, allocating large buffers on the stack can lead to stack overflows and system instability. By dynamically allocating memory from the heap (e.g., using pvPortMalloc()), the task can safely create and manage large data structures, then pass their addresses through the queue.
Additionally, the sending task should never free the memory after placing the pointer into the queue. This is because the sender has no way of knowing when the receiving task has finished processing the data. Prematurely freeing the memory could lead to undefined behavior that can lead to system failure.
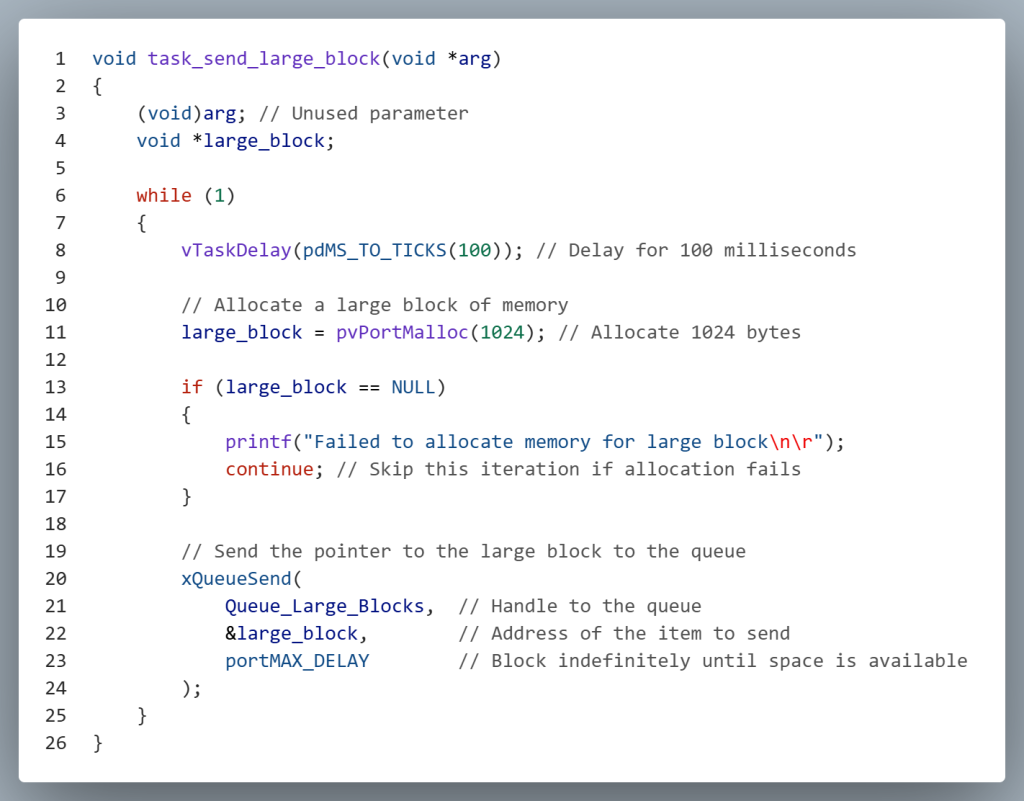
In a Queue-by-Reference implementation, the task that receives the message is responsible for freeing the memory once it has finished processing it. Since the sender only passes a pointer to the data and does not know when the receiver is done using it, it is important that the receiving task manages the memory lifecycle. This ensures that memory is properly returned to the heap, preventing memory leaks and maintaining system stability.
